Stat::Fit
You no longer need Stat::Fit to turn data into a distribution. The Expression Builder does it directly: on its Fit data to distribution tab, paste or import your data and it fits the built-in distributions, ranks them, and gives you a ready-to-use expression. The original Stat::Fit reference is kept below for anyone working from earlier versions.
LegacyHow this worked in the previous version
Summary
Section titled “Summary”- Click Stat::Fit from the Tools menu.
- Copy the column of data that you want to use within Stat::Fit.
- Click in the open space directly across from the number 1 and press CTRL + V to paste data.
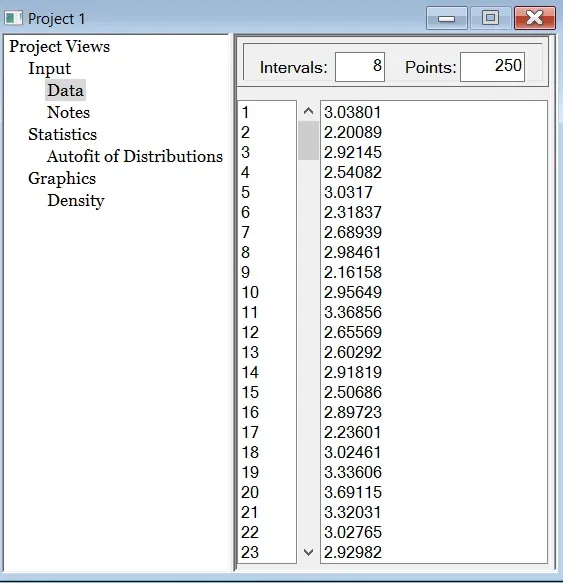
- Click the Auto::Fit button.
- In the Auto::Fit dialog, select unbounded, lower bound or assigned lower bound and click OK.
- Users with statistical background may enjoy experimenting with the power of Stat::Fit here.
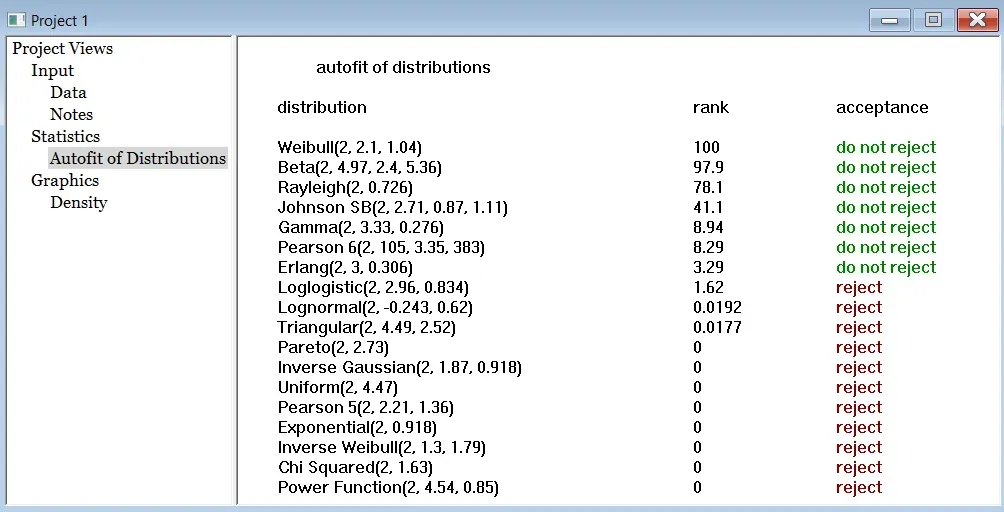
- Click on the distribution you wish to use in the dialog displayed. This will generate the Comparison graph.
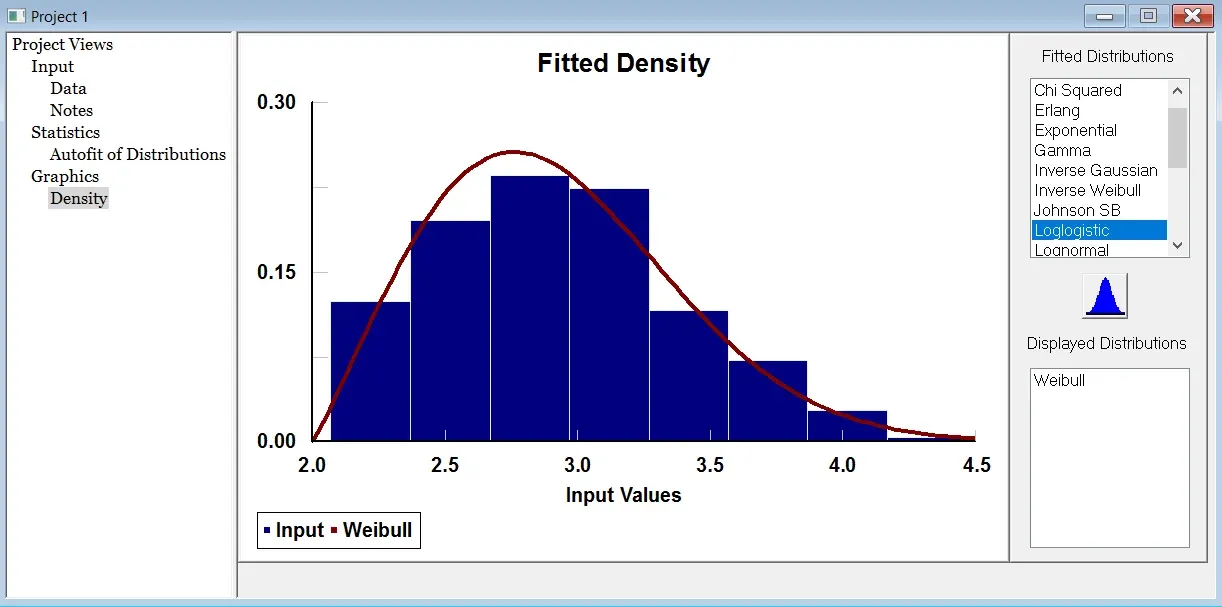
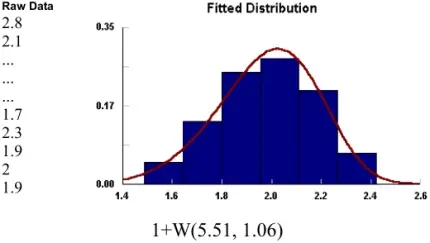
- The Comparison graph allows you to compare your actual data against the selected distribution. The bars represent your data, while the line represents the distribution that will fit that data.
- Other comparative graphs are accessible through the Results option of the Fit menu.
- With the best distribution selected, click the Export button. Click OK to export the distribution to the clipboard.
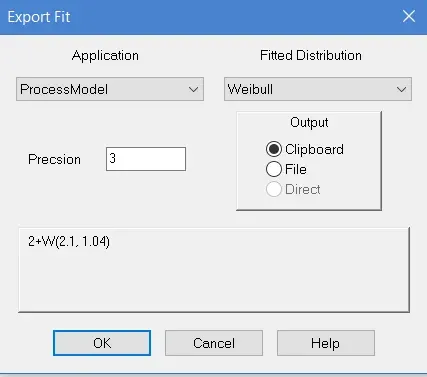
- Now return to ProcessModel and paste the distribution in the desired field or Action logic using the CTRL-V shortcut.
Detailed Information
Section titled “Detailed Information”Stat::Fit® is a comprehensive yet user-friendly curve-fitting package. Stat::Fit will take raw data from spreadsheets, text files, or manual input and convert that data into the appropriate distribution for instant input into ProcessModel software.
It automatically fits continuous distributions, compares distribution types, and provides an absolute measure of each distribution’s acceptability. It also translates the fitted distribution into specific forms for use in ProcessModel products. It is developed by our technology partners at Geer Mountain Software.
Stat::Fit statistically fits your data to the most useful analytical distribution. Its operation is intuitive, yet its help file is extensive. The Auto::Fit function automatically fits continuous distributions, provides relative comparisons between distribution types, and an absolute measure of each distribution’s acceptability. The Export function translates the fitted distribution into ProcessModel. Some of the features are included below.
Stat::Fit takes raw data (e.g. collected service times) and turns them into a single distribution that represents the collected data. For example, data collected on the length of breakdowns can be turned into a single distribution and be placed in a ProcessModel field.
Stat::Fit is accessed from the Tools menu. It allows you to improve the accuracy of your models by using collected data to determine the best distribution to use in order to reflect that data (See Distributions).
Distribution Fitting
Section titled “Distribution Fitting”For Many distributions: Beta, Binomial, Chi-Squared, Erlang, Exponential, Extreme Value IA, Extreme Value IB, Gamma, Geometric, Inverse Gaussian, Inverse Weibull, Johnson SB, Johnson SU, Logarithmic, Logistic, Loglogistic, Lognormal, Normal, Pareto, Pearson V, Pearson VI, Poisson, Power Function, Rayleigh, Triangular, Uniform, Weibull.
Descriptive Statistics: Mean, Median, Mode, Standard Deviation, Variance, Coefficient of Variation, Skewness, Kurtosis.
Parameter Estimates: Maximum Likelihood, Moments.
Goodness of Fit Tests: Chi-squared, Kolmogorov-Smirnov, Anderson-Darling.
Graphical Analysis: Density graphs, Distribution Graphs, Difference graphs, Box Plots, Q-Q plot, P-P plot, Scatter plot, Autocorrelation graphs.
Additional Features: Built-in random variate generator, Data manipulation options, Distribution Viewer, Distribution Percentiles.
Continuous Distributions vs. Discrete Distributions
Section titled “Continuous Distributions vs. Discrete Distributions”Distribution fittings are built-in functions that generate random numbers using predetermined patterns. Distributions may be discrete, randomly returning one value among a specified list of values, or they can be continuous and interpolate randomly according to the pattern provided by the input table or parameters. There are several steps in determining the best distribution to use given raw data from observations of the process being modeled. First, you must determine whether the data is discrete or continuous, then follow the appropriate instructions. For instructions on finding the best discrete or continuous distribution, see Discrete distribution below.
Stat::Fit is capable of much more than fitting data to distributions, but you need only take advantage of a few of its easy-to-use features when fitting your data to a ProcessModel distribution.
Continuous Distribution
Section titled “Continuous Distribution”The following example shows you how Stat::Fit can help you create more accurate models. A bank wants to model its teller operations, including the amount of time that it takes to serve each customer. Therefore, for a week, the time each customer spent with a teller is recorded. The data is entered in a text file which can be read by Stat::Fit. Using Stat::Fit, the data is analyzed and an activity time distribution is found that accurately reflects the amount of time required to serve a customer.
Discrete Distribution
Section titled “Discrete Distribution”The following example shows how a restaurant could use ProcessModel to model its seating operation. The number of customers is a quantity of discrete entities. Therefore, the Stat::Fit component of ProcessModel would take data about the number of customers who enter in each group, create a discrete distribution to represent that data, and place the distribution in the Quantity field for Arrivals in the ProcessModel for the restaurant.
Determine the best discrete distribution from raw data
Section titled “Determine the best discrete distribution from raw data”- Click Stat::Fit from the Tools menu.
- Copy the column of data that you want to use within Stat::Fit.
- Click in the open space directly across from the number 1 and press CTRL + V to paste data.
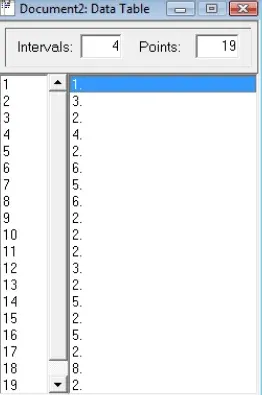
- Click the Auto::Fit button
 .
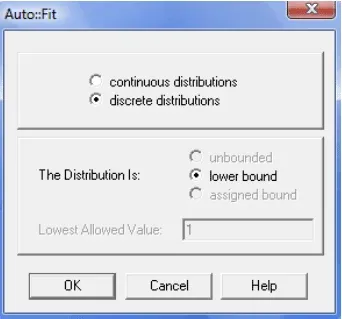
. - In the Auto::Fit dialog, select discrete distributions as shown below and click OK.
Stat::Fit then calculates the best distribution choices and displays them along with their rank (the higher the rank, the better the fit).
- Click on the name of the distribution that best fits the data.
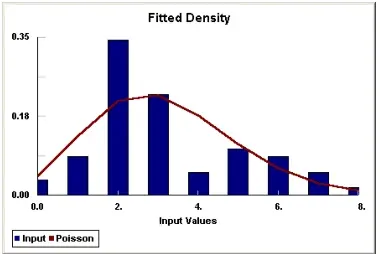
- With the best distribution found, follow the instructions for exporting data to ProcessModel found in fitting continuous data.
Replications in Stat::Fit
Section titled “Replications in Stat::Fit”Find out how many process simulation replications should be run in order to accurately represent a system. There are formulas to calculate replications required, even better one of the formulas has been automated in Stat::Fit, a fantastic tool provided with ProcessModel. Stat::Fit is found on the Tools/Stat::Fit menu.
The Replications command allows the user to calculate the number of independent data points, or replications, of an experiment necessary to provide a given range, or confidence interval, for the estimate of a parameter. The confidence interval is given for the confidence level specified, with of default of 0.95. The resulting number of replications is calculated using the t distribution.
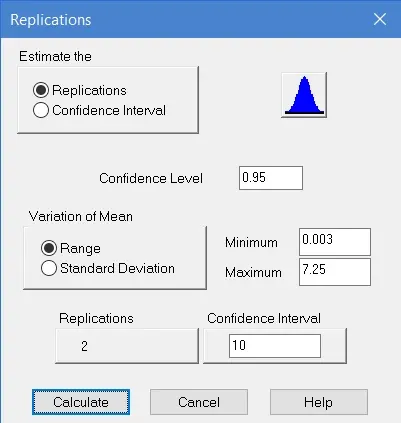
The expected variation of the parameter must be specified by either its expected maximum range or its expected standard deviation. Quite frequently, this variation is calculated by pilot runs of the experiment or simulation but can be chosen by experience if necessary. Be aware that this is just an initial value for the required replications, and should be refined as further data are available.
Alternatively, the confidence interval for a given estimate of a parameter can be calculated from the known number of replications and the expected or estimated variation of the parameter.
Distributions and their Usage
Section titled “Distributions and their Usage”Following is a list of distributions and their general uses in ProcessModel. These distributions can be determined by using Stat::Fit and then used within different areas of ProcessModel.
| Distribution | Usage |
|---|---|
| Beta | The Beta distribution is a continuous distribution that has both upper and lower finite bounds. Because many real situations can be bounded in this way, the Beta distribution can be used empirically to estimate the actual distribution before much data is available. Even when data is available, the Beta distribution should fit most data in a reasonable fashion, although it may not be the best fit. For more information, see Beta Distribution. |
| Binomial | The Binomial distribution is a discrete distribution bounded by [0,n]. Typically, it is used where a single trial is repeated over and over, such as the tossing of a coin. The parameter, p, is the probability of the event, either heads or tails, either occurring or not occurring. Each single trial is assumed to be independent of all others. The Binomial distribution can be used to represent the sampling of defective parts in a stable process, and other event sampling tests where the probability of the event is known to be constant or nearly so. |
| Exponential | The Exponential distribution is continuous and is frequently used to represent the time between random occurrences, such as the time between arrivals at a specific location in a queuing model or the time between failures in reliability models. It has also been used to represent the service times of a specific operation. |
| Erlang | The Erlang distribution is a continuous distribution bounded on the lower side. The Erlang distribution has been used extensively in reliability and in queuing theory. |
| Gamma | The Gamma distribution has been used to represent lifetimes, lead times, personal income data, and service times. |
| Geometric | The Geometric distribution has been used for inventory demand, marketing survey returns, etc. |
| Inverse Gaussian | The Inverse Gaussian distribution is a continuous distribution with a bound on the lower side. This distribution can be used to represent reliability and lifetimes, and repair time. |
| Lognormal | The Lognormal distribution is a continuous distribution bounded on the lower side. This distribution can be used to model the duration of sickness absence, physicians’ consultant time, lifetime distributions in reliability, distribution of income, employee retention, and many applications modeling weight, height, etc. For more information, see Lognormal Conversion. |
| Normal | The Normal distribution is frequently used to represent symmetrical data but suffers from being unbounded in both directions. If the data is known to have a lower bound, it may be better represented by suitable parametrization of the Lognormal, Weibull, or Gamma distributions. See distributions for a description of the input parameters. |
| Poisson | The Poisson distribution is a discrete distribution bounded at 0 on the low side and unbounded on the high side. The Poisson distribution finds frequent use because it represents the infrequent occurrence of events whose rate is constant. This includes many types of events in time or space such as arrivals of telephone calls, defects in semiconductors manufacturing, and defects in all aspects of quality control. |
| Pearson5 | The Pearson 5 distribution is a continuous distribution with a bound on the lower side. The Pearson 5 distribution is useful for modeling time delays where some minimum delay value is almost assured and the maximum time is unbounded and variably long, such as time to complete a difficult task, time to respond to an emergency, and time to repair a tool, etc. |
| Pearson6 | The Pearson 6 distribution is a continuous distribution bounded on the low side. |
| Triangular | The Triangular distribution is a continuous distribution bounded on both sides. The Triangular distribution is often used when no or little data is available; it is a good starting point for approximating data, but it is rarely an accurate representation of a data set. See distributions for a description of the input parameters. For more information, see Triangular Distribution. |
| Uniform | The Uniform distribution is a continuous distribution bounded on both sides. Its density does not depend on the value of x. The Uniform distribution is used to represent a random variable with constant likelihood of being in any small interval between min and max. See distributions for a description of the input parameters. For more information, see Uniform Distribution. |
| User-Defined | The User-Defined distribution is a discrete distribution defined by the probability of obtaining each value. See distributions for a description of the input parameters. |
| Weibull | The Weibull distribution is a continuous distribution bounded on the lower side. In particular, the Weibull distribution is used to represent wear-out lifetimes in reliability, health-related issues, and duration of industrial stoppages. |